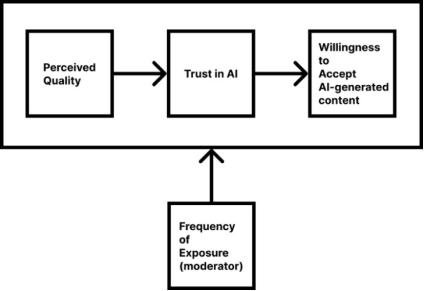
This study investigates the impact of perceived content quality and frequency of interaction with AI-generated materials on users' willingness to accept such automated content without additional human editing. Given the expanding role of artificial intelligence in digital communications, exploring user acceptance of AI-produced content is increasingly important. Utilizing a quantitative research method, data was collected from 1,118 internet users familiar with digital content via computer-assisted web interviewing (CAWI). Statistical techniques, specifically Spearman’s correlation and ordinal logistic regression, were employed to pinpoint essential determinants of acceptance. Findings revealed that a higher perceived quality of AI-generated content significantly enhances user willingness to accept it without human review. Conversely, the analysis showed a slight negative correlation regarding interaction frequency, indicating that repeated exposure could heighten users' awareness of imperfections inherent in AI-generated materials, thereby potentially decreasing their trust and willingness to adopt it autonomously. These findings highlight the strategic importance of prioritising content quality over exposure frequency. Limitations regarding the representativeness of the sample and the moderate explanatory power of the statistical model indicate the need for future research to explore additional moderating factors, such as digital literacy, demographic characteristics, and general attitudes towards innovation.
| Published in | European Business & Management (Volume 11, Issue 2) |
| DOI | 10.11648/j.ebm.20251102.12 |
| Page(s) | 40-47 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2025. Published by Science Publishing Group |
Artificial Intelligence, Automated Content Generation, Trust in AI, AI-generated Content, Human-AI Interaction, Technology Adoption
N | Marginal Percentage | ||
|---|---|---|---|
Acceptance of AI content | 1 | 707 | 63,2% |
2 | 96 | 8,6% | |
3 | 206 | 18,4% | |
4 | 109 | 9,7% | |
Valid | 1118 | 100,0% | |
Missing | 191 | ||
Total | 1309 | ||
AI quality | AI encounter frequency | Acceptance of AI content | |||
|---|---|---|---|---|---|
Spearman's rho | AI quality | Correlation Coefficient | 1,000 | ,050 | ,270** |
Sig. (2-tailed) | . | ,097 | <,001 | ||
N | 1119 | 1118 | 1119 | ||
AI encounter frequency | Correlation Coefficient | ,050 | 1,000 | -,013 | |
Sig. (2-tailed) | ,097 | . | ,644 | ||
N | 1118 | 1306 | 1306 | ||
Acceptance of AI content | Correlation Coefficient | ,270** | -,013 | 1,000 | |
Sig. (2-tailed) | <,001 | ,644 | . | ||
N | 1119 | 1306 | 1307 | ||
**. Correlation is significant at the 0.01 level (2-tailed). | |||||
Model | -2 Log Likelihood | Chi-Square | df | Sig. |
|---|---|---|---|---|
Intercept Only | 302,014 | |||
Final | 216,645 | 85,369 | 2 | <,001 |
Link function: Logit. | ||||
Chi-Square | df | Sig. | |
|---|---|---|---|
Pearson | 75,288 | 43 | ,002 |
Deviance | 77,051 | 43 | ,001 |
Link function: Logit. | |||
Cox and Snell | ,074 |
Nagelkerke | ,084 |
McFadden | ,037 |
Link function: Logit. | |
Estimate | Std. Error | Wald | df | Sig. | 95% Confidence Interval | |||
|---|---|---|---|---|---|---|---|---|
Lower Bound | Upper Bound | |||||||
Threshold | [AI content acceptance = 1] | 1,383 | ,328 | 17,813 | 1 | <,001 | ,741 | 2,025 |
[AI content acceptance = 2] | 1,804 | ,330 | 29,940 | 1 | <,001 | 1,158 | 2,450 | |
[AI content acceptance = 3] | 3,146 | ,341 | 85,335 | 1 | <,001 | 2,478 | 3,813 | |
Location | AI quality | ,576 | ,066 | 75,148 | 1 | <,001 | ,445 | ,706 |
AI encounter frequency | -,182 | ,085 | 4,559 | 1 | ,033 | -,349 | -,015 | |
Link function: Logit. | ||||||||
Model | -2 Log Likelihood | Chi-Square | df | Sig. |
|---|---|---|---|---|
Null Hypothesis | 216,645 | |||
General | 205,692 | 10,953 | 4 | ,027 |
The null hypothesis states that the location parameters (slope coefficients) are the same across response categories. | ||||
Link function: Logit. | ||||
CAWI | Computer Assisted Web Interviewing |
AI | Artificial Intelligence |
TAM | Technology Acceptance Model |
| [1] | ALQAHTANI, Tariq et al. 2023. The emergent role of artificial intelligence, natural learning processing, and large language models in higher education and research. Research in Social and Administrative Pharmacy. Vol. 19, no. 8, pp. 1236-1242. |
| [2] | AMANKWAH-AMOAH, Joseph et al. 2024. The impending disruption of creative industries by generative AI: Opportunities, challenges, and research agenda. International Journal of Information Management. Vol. 79, s. 102759. |
| [3] | ELKHATAT, Ahmed M., ELSAID, Khaled and ALMEER, Saeed, 2023. Evaluating the efficacy of AI content detection tools in differentiating between human and AI-generated text. International Journal for Educational Integrity. Vol. 19, no. 1, p. 17. |
| [4] | FEUERRIEGEL, Stefan et al. 2024. Generative AI. Business & Information Systems Engineering. Vol. 66, no. 1, pp. 111-126. |
| [5] | MOLINA, Maria D. and SUNDAR, S. Shyam, 2024. Does distrust in humans predict greater trust in AI? Role of individual differences in user responses to content moderation. New Media & Society. vol. 26, no. 6, pp. 3638-3656. |
| [6] | CHANDRA, Shalini, SHIRISH, Anuragini and SRIVASTAVA, Shirish C., 2022. To Be or Not to Be... Human? Theorizing the Role of Human-Like Competencies in Conversational Artificial Intelligence Agents. Journal of Management Information Systems. Vol. 39, No. 4, pp. 969-1005. |
| [7] | KANG, Hyunjin and LOU, Chen, 2022. AI agency vs. human agency: understanding human-AI interactions on TikTok and their implications for user engagement. HUMPHREYS, Lee (ed.), Journal of Computer-Mediated Communication. Vol. 27, No. 5, p. zmac014. |
| [8] | OVIEDO-TRESPALACIOS, Oscar et al. 2023. The risks of using ChatGPT to obtain common safety-related information and advice. Safety Science. Vol. 167, s. 106244. |
| [9] | CHOUNG, Hyesun, DAVID, Prabu and ROSS, Arun, 2023. Trust in AI and Its Role in the Acceptance of AI Technologies. international Journal of Human-Computer Interaction. Vol. 39, no. 9, pp. 1727-1739. |
| [10] | KAUR, Davinder et al. 2023. Trustworthy Artificial Intelligence: A Review. ACM Computing Surveys. Vol. 55, no. 2, pp. 1-38. |
| [11] | LIU, Guangxiang a MA, Chaojun, 2024. Measuring EFL learners’ use of ChatGPT in informal digital learning of English based on the technology acceptance model. Innovation in Language Learning and Teaching. Vol. 18, č. 2, s. 125–138. |
| [12] | SU, Diep Ngoc et al., 2022. Modeling consumers’ trust in mobile food delivery apps: perspectives of technology acceptance model, mobile service quality and personalization-privacy theory. Journal of Hospitality Marketing & Management. Vol. 31, č. 5, s. 535–569. |
| [13] | CASTELO, Noah et al., 2023. Understanding and Improving Consumer Reactions to Service Bots. COTTE, June a WERTENBROCH, Klaus (ed.), Journal of Consumer Research. Vol. 50, č. 4, s. 848–863. |
| [14] | SCHEPMAN, Astrid a RODWAY, Paul, 2023. The General Attitudes towards Artificial Intelligence Scale (GAAIS): Confirmatory Validation and Associations with Personality, Corporate Distrust, and General Trust. International Journal of Human–Computer Interaction. Vol. 39, č. 13, s. 2724–2741. |
| [15] | GILAT, Ron and COLE, Brian J., 2023. How Will Artificial Intelligence Affect Scientific Writing, Reviewing and Editing? The Future is Here.... Arthroscopy: The Journal of Arthroscopic & Related Surgery. Vol. 39, No. 5, pp. 1119-1120. |
| [16] | ZHOU, Jiawei et al., 2023. Synthetic Lies: Understanding AI-Generated Misinformation and Evaluating Algorithmic and Human Solutions. V: Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems, s. 1–20. Hamburg Germany: ACM. 19 apríl 2023. ISBN 9781450394215. |
| [17] | KSHETRI, Nir et al. 2024. Generative artificial intelligence in marketing: Applications, opportunities, challenges, and research agenda. International Journal of Information Management. Vol. 75, s. 102716. |
| [18] | BRYNJOLFSSON, Erik, 2022. The Turing Trap: The Promise & Peril of Human-Like Artificial Intelligence. Daedalus. Vol. 151, no. 2, pp. 272-287. |
| [19] | WACH, Krzysztof et al. 2023. The dark side of generative artificial intelligence: A critical analysis of controversies and risks of ChatGPT. Entrepreneurial Business and Economics Review. Vol. 11, no. 2, pp. 7-30. |
| [20] | MENON, Devadas and SHILPA, K, 2023. "Chatting with ChatGPT": Analyzing the factors influencing users' intention to use Open AI's ChatGPT using the UTAUT model. Heliyon. Vol. 9, no. 11, p. e20962. |
| [21] | BÜCHI, Moritz, FESTIC, Noemi and LATZER, Michael, 2022. the Chilling Effects of Digital Dataveillance: a Theoretical Model and an Empirical Research Agenda. Big Data & Society. vol. 9, No. 1, p. 20539517211065368. |
APA Style
Kubovics, M. (2025). Willingness of Users to Accept AI Content Creation. European Business & Management, 11(2), 40-47. https://doi.org/10.11648/j.ebm.20251102.12
ACS Style
Kubovics, M. Willingness of Users to Accept AI Content Creation. Eur. Bus. Manag. 2025, 11(2), 40-47. doi: 10.11648/j.ebm.20251102.12
@article{10.11648/j.ebm.20251102.12,
author = {Michal Kubovics},
title = {Willingness of Users to Accept AI Content Creation},
journal = {European Business & Management},
volume = {11},
number = {2},
pages = {40-47},
doi = {10.11648/j.ebm.20251102.12},
url = {https://doi.org/10.11648/j.ebm.20251102.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.ebm.20251102.12},
abstract = {This study investigates the impact of perceived content quality and frequency of interaction with AI-generated materials on users' willingness to accept such automated content without additional human editing. Given the expanding role of artificial intelligence in digital communications, exploring user acceptance of AI-produced content is increasingly important. Utilizing a quantitative research method, data was collected from 1,118 internet users familiar with digital content via computer-assisted web interviewing (CAWI). Statistical techniques, specifically Spearman’s correlation and ordinal logistic regression, were employed to pinpoint essential determinants of acceptance. Findings revealed that a higher perceived quality of AI-generated content significantly enhances user willingness to accept it without human review. Conversely, the analysis showed a slight negative correlation regarding interaction frequency, indicating that repeated exposure could heighten users' awareness of imperfections inherent in AI-generated materials, thereby potentially decreasing their trust and willingness to adopt it autonomously. These findings highlight the strategic importance of prioritising content quality over exposure frequency. Limitations regarding the representativeness of the sample and the moderate explanatory power of the statistical model indicate the need for future research to explore additional moderating factors, such as digital literacy, demographic characteristics, and general attitudes towards innovation.},
year = {2025}
}
TY - JOUR T1 - Willingness of Users to Accept AI Content Creation AU - Michal Kubovics Y1 - 2025/06/26 PY - 2025 N1 - https://doi.org/10.11648/j.ebm.20251102.12 DO - 10.11648/j.ebm.20251102.12 T2 - European Business & Management JF - European Business & Management JO - European Business & Management SP - 40 EP - 47 PB - Science Publishing Group SN - 2575-5811 UR - https://doi.org/10.11648/j.ebm.20251102.12 AB - This study investigates the impact of perceived content quality and frequency of interaction with AI-generated materials on users' willingness to accept such automated content without additional human editing. Given the expanding role of artificial intelligence in digital communications, exploring user acceptance of AI-produced content is increasingly important. Utilizing a quantitative research method, data was collected from 1,118 internet users familiar with digital content via computer-assisted web interviewing (CAWI). Statistical techniques, specifically Spearman’s correlation and ordinal logistic regression, were employed to pinpoint essential determinants of acceptance. Findings revealed that a higher perceived quality of AI-generated content significantly enhances user willingness to accept it without human review. Conversely, the analysis showed a slight negative correlation regarding interaction frequency, indicating that repeated exposure could heighten users' awareness of imperfections inherent in AI-generated materials, thereby potentially decreasing their trust and willingness to adopt it autonomously. These findings highlight the strategic importance of prioritising content quality over exposure frequency. Limitations regarding the representativeness of the sample and the moderate explanatory power of the statistical model indicate the need for future research to explore additional moderating factors, such as digital literacy, demographic characteristics, and general attitudes towards innovation. VL - 11 IS - 2 ER -
Faculty of Mass Media Communication, University of Ss. Cyril and Methodius, Trnava, Slovakia
Information