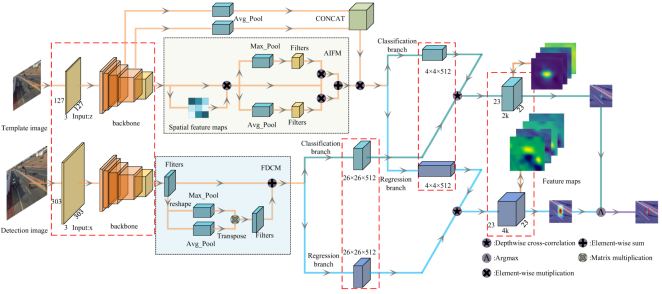
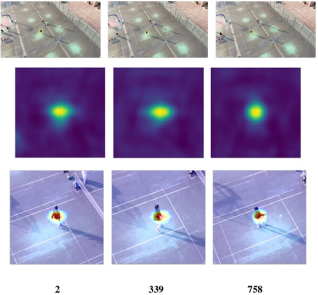
Unmanned aerial vehicles (UAVs) visual tracking is an important research direction. The tracking object is lost due to the problems of target occlusion, illumination variation, flight vibration and so on. Therefore, based on a Siamese network, this study proposes a UAVs visual tracker named SiamDFT++ to enhance the correlation of depth features. First, the network width of the three-layer convolution after the full convolution neural network is doubled, and the appearance information of the target is fully utilized to complete the feature extraction of the template frame and the detection frame. Then, the attention information fusion module and feature deep convolution module are proposed in the template branch and the detection branch, respectively. The feature correlation calculation methods of the two depths can effectively suppress the background information, enhance the correlation between pixel pairs, and efficiently complete the tasks of classification and regression. Furthermore, this study makes full use of shallow features to enhance the extraction of object features. Finally, this study uses the methods of deep cross-correlation operation and complete intersection over union to complete the matching and location tasks. The experimental results show that the tracker has strong robustness in UAVs short-term tracking scenes and long-term tracking scenes.
| Published in | Automation, Control and Intelligent Systems (Volume 12, Issue 2) |
| DOI | 10.11648/j.acis.20241202.12 |
| Page(s) | 35-47 |
| Creative Commons |
This is an Open Access article, distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution and reproduction in any medium or format, provided the original work is properly cited. |
| Copyright |
Copyright © The Author(s), 2024. Published by Science Publishing Group |
Visual Tracking, Unmanned Aerial Vehicles, Convolutional Feature, Real-time Remote Sensing
layers | stride | kernel | channel | template | detection |
|---|---|---|---|---|---|
Input | - | - | - | 127×127 | 303×303 |
Conv1 | 2 | 11×11 | 96 | 59×59 | 147×147 |
MaxPool1 | 2 | 3×3 | 96 | 29×29 | 73×73 |
Conv2 | 1 | 5×5 | 256 | 25×25 | 69×69 |
MaxPool2 | 2 | 3×3 | 256 | 12×12 | 34×34 |
Conv3 | 1 | 3×3 | 768 | 10×10 | 32×32 |
Conv4 | 1 | 3×3 | 768 | 8×8 | 30×30 |
Conv5 | 1 | 3×3 | 512 | 6×6 | 28×28 |
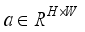 . Vertical and horizontal directions can be calculated as:
. Vertical and horizontal directions can be calculated as: 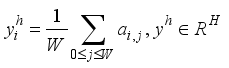 (1)
(1) 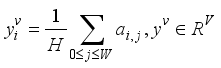 (2)
(2) 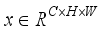 ,
, 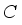 represents the number of channels, and
represents the number of channels, and 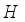 and
and 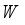 represent the height and width, respectively. Then, one-dimensional convolution with kernel 3 is used to modulate the feature information of the adjacent position and the current position to obtain the spatial information of the remote global context.
represent the height and width, respectively. Then, one-dimensional convolution with kernel 3 is used to modulate the feature information of the adjacent position and the current position to obtain the spatial information of the remote global context. 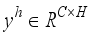 and
and 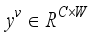 can be gained respectively. By fusing
can be gained respectively. By fusing 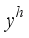 and
and 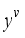 ,
, 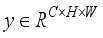 can be gained. The mathematical expression is:
can be gained. The mathematical expression is: 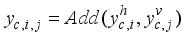 (3)
(3) 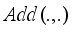 denotes element-wise sum among feature maps. Next,
denotes element-wise sum among feature maps. Next, 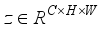 can be gained, and the mathematical expression is as follows:
can be gained, and the mathematical expression is as follows: 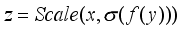 (4)
(4) 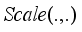 describes elementwise mutiplication.
describes elementwise mutiplication. 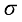 describes the sigmoid function. The pooling window sizes are given as 16×16 and 12×12 respectively, and batch normalization (BN) and ReLU operations are performed after each layer of convolution to further boost the feature extraction capability. Channel
describes the sigmoid function. The pooling window sizes are given as 16×16 and 12×12 respectively, and batch normalization (BN) and ReLU operations are performed after each layer of convolution to further boost the feature extraction capability. Channel 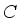 can be expressed as:
can be expressed as: 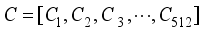 (5)
(5) 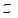 is further processed using global maximum pooling (GMP) and global average pooling (GAP) to obtain rich context information. In this tracker, the band matrix
is further processed using global maximum pooling (GMP) and global average pooling (GAP) to obtain rich context information. In this tracker, the band matrix 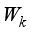 is used to express the learned channel weight information, so that the number of cross-channel interactions can be implemented.
is used to express the learned channel weight information, so that the number of cross-channel interactions can be implemented. 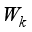 can be formulated as:
can be formulated as: 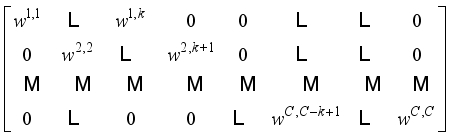 (6)
(6) 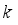 weight information adjacent to
weight information adjacent to 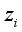 is considered, which can be formulated as:
is considered, which can be formulated as: 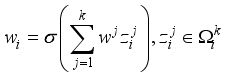 (7)
(7) 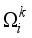 denotes the complete set of
denotes the complete set of 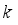 channels adjoining to
channels adjoining to 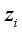 , and
, and 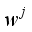 indicates the shared weight information. Then, the strategy can be realized by fast one-dimensional convolution (represented as
indicates the shared weight information. Then, the strategy can be realized by fast one-dimensional convolution (represented as 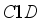 ) with convolution kernel size of
) with convolution kernel size of 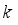 . Mathematical, it can be expressed as:
. Mathematical, it can be expressed as: 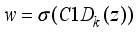 (8)
(8) 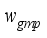 and
and 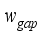 respectively. Mathematical, they can be expressed as:
respectively. Mathematical, they can be expressed as: 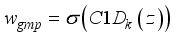 (9)
(9) 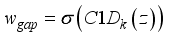 (10)
(10) 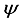 is:
is: 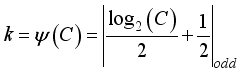 (11)
(11) 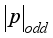 denotes the nearest odd number closest to
denotes the nearest odd number closest to 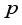 , and then
, and then 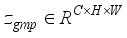 and
and 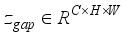 are obtained, which can be expressed as:
are obtained, which can be expressed as: 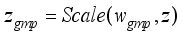 (12)
(12) 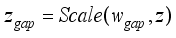 (13)
(13) 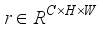 is obtained after feature fusion, i.e.:
is obtained after feature fusion, i.e.: 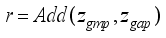 (14)
(14) 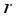 , the features are further processed by BN and ReLU. Then, one-dimensional convolution and multilayer fusion are performed.
, the features are further processed by BN and ReLU. Then, one-dimensional convolution and multilayer fusion are performed. 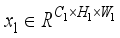 and
and 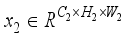 , which represent the feature maps of the third and fourth layers of the backbone network respectively. Then, after GAP calculation, this study concatenates the feature information, and obtain the prediction result through a multilayer perceptron (MLP). After reshaping, elementwise mutiplication is employed to strengthen the aggregation of shallow feature information. Thus,
, which represent the feature maps of the third and fourth layers of the backbone network respectively. Then, after GAP calculation, this study concatenates the feature information, and obtain the prediction result through a multilayer perceptron (MLP). After reshaping, elementwise mutiplication is employed to strengthen the aggregation of shallow feature information. Thus, 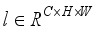 is obtained, i.e.:
is obtained, i.e.: 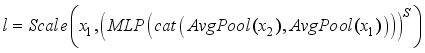 (15)
(15) 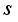 denotes reshape and
denotes reshape and 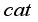 denotes concat.
denotes concat. 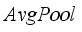 denotes GAP calculation. MLP represents two fully connected layers with BN and ReLU in each layer. After CycleMLP, two layers of convolution with a convolution kernel size of 3 are used to complete the calculation of deep features. Again with the deep feature fusion, highlighting the target information, the obtained
denotes GAP calculation. MLP represents two fully connected layers with BN and ReLU in each layer. After CycleMLP, two layers of convolution with a convolution kernel size of 3 are used to complete the calculation of deep features. Again with the deep feature fusion, highlighting the target information, the obtained 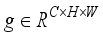 mathematical formula can be expressed as:
mathematical formula can be expressed as: 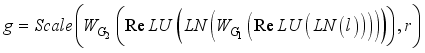 (16)
(16) 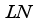 represents the batch normalization, and
represents the batch normalization, and 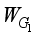 and
and 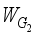 denote the weight parameters learned by the two layers of convolution, respectively. Finally, the learned weight vector can be obtained, and the final channel
denote the weight parameters learned by the two layers of convolution, respectively. Finally, the learned weight vector can be obtained, and the final channel 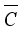 can be expressed as:
can be expressed as: 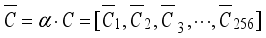 (17)
(17) 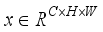 , where
, where 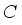 represents the number of channels and
represents the number of channels and 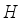 and
and 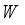 represent the height and width, respectively. First, after convolution with a kernel size of 1×1, the feature information is processed by batch normalization and an activation function. A large number of experiments show that too many detection frame channels will carry a large amount of feature information irrelevant to the target. Therefore, compressing the number of channels is an effective method to learn target features, and also reduces the number of parameters. In the experiment,
represent the height and width, respectively. First, after convolution with a kernel size of 1×1, the feature information is processed by batch normalization and an activation function. A large number of experiments show that too many detection frame channels will carry a large amount of feature information irrelevant to the target. Therefore, compressing the number of channels is an effective method to learn target features, and also reduces the number of parameters. In the experiment, 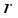 is the compression channel ratio, and the size is 8. Then the obtained feature information is reshaped to obtain
is the compression channel ratio, and the size is 8. Then the obtained feature information is reshaped to obtain 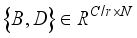 where
where 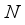 represents
represents 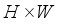 , i.e.:
, i.e.: 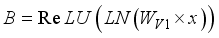 (18)
(18) 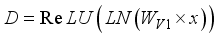 (19)
(19) 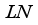 represents the batch normalization operation, and
represents the batch normalization operation, and 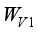 represents the weight information learned by deep convolution.
represents the weight information learned by deep convolution. 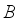 and
and 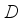 learn the feature information of the target through GAP and GMP respectively, and complete the matrix multiplication operation. After taking the maximum value of the obtained output feature and completing the reshaping, the normalized probability distribution of the target feature is obtained through the softmax function, which can adaptively learn the spatial position information of the target and output
learn the feature information of the target through GAP and GMP respectively, and complete the matrix multiplication operation. After taking the maximum value of the obtained output feature and completing the reshaping, the normalized probability distribution of the target feature is obtained through the softmax function, which can adaptively learn the spatial position information of the target and output 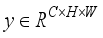 can be expressed as:
can be expressed as: 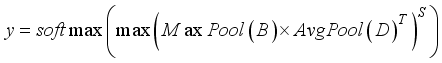 (20)
(20) 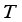 represents transpose and
represents transpose and 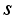 represents reshape. Then, this study extend the channel through convolution and allocate various weight information to learn the relevant features of the target, to realize the information fusion of the features and attain the final output
represents reshape. Then, this study extend the channel through convolution and allocate various weight information to learn the relevant features of the target, to realize the information fusion of the features and attain the final output 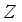 , i.e.:
, i.e.: 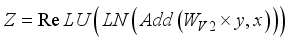 (21)
(21) 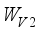 represents the model weight learned by extended channel convolution.
represents the model weight learned by extended channel convolution. Trackers | Venue | DP | AUC |
|---|---|---|---|
SAMF | ECCV2014 | 0.593 | 0.396 |
DSST | BMVC2014 | 0.586 | 0.356 |
KCF | TPAMI2015 | 0.523 | 0.331 |
SRDCF | ICCV2015 | 0.676 | 0.463 |
Staple | CVPR2016 | 0.595 | 0.409 |
SiamFC | ECCV2016 | 0.696 | 0.480 |
MCPF | CVPR2017 | 0.718 | 0.473 |
BACF | ICCV2017 | 0.660 | 0.459 |
ECO_HC | CVPR2017 | 0.710 | 0.496 |
DeepSTRCF | CVPR2018 | 0.705 | 0.508 |
MCCT | CVPR2018 | 0.734 | 0.507 |
SiamRPN | CVPR2018 | 0.749 | 0.528 |
TADT | CVPR2019 | 0.727 | 0.520 |
ARCF | ICCV2019 | 0.671 | 0.468 |
UDT | CVPR2019 | 0.668 | 0.477 |
AutoTrack | CVPR2020 | 0.689 | 0.472 |
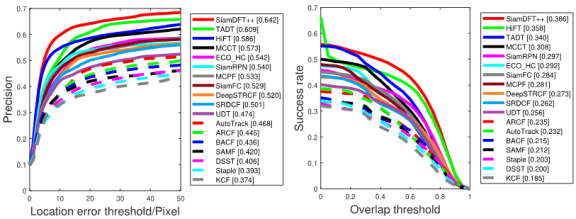
HiFT | ICCV2021 | 0.787 | 0.589 |
SiamDFT++ | 0.811 | 0.592 |
scence | Camera Motion Illumination Variation | |||
|---|---|---|---|---|
DP | AUC | DP | AUC | |
SAMF | 0.561 | 0.381 | 0.478 | 0.312 |
DSST | 0.520 | 0.322 | 0.524 | 0.307 |
KCF | 0.483 | 0.310 | 0.418 | 0.270 |
SRDCF | 0.627 | 0.439 | 0.600 | 0.395 |
Staple | 0.544 | 0.386 | 0.498 | 0.362 |
SiamFC | 0.684 | 0.482 | 0.603 | 0.391 |
MCPF | 0.700 | 0.463 | 0.659 | 0.424 |
BACF | 0.639 | 0.450 | 0.525 | 0.356 |
ECO_HC | 0.676 | 0.476 | 0.628 | 0.407 |
DeepSTRCF | 0.696 | 0.509 | 0.664 | 0.444 |
MCCT | 0.720 | 0.508 | 0.704 | 0.466 |
SiamRPN | 0.750 | 0.537 | 0.665 | 0.456 |
TADT | 0.723 | 0.518 | 0.669 | 0.462 |
ARCF | 0.647 | 0.455 | 0.595 | 0.392 |
UDT | 0.654 | 0.467 | 0.599 | 0.401 |
AutoTrack | 0.658 | 0.458 | 0.617 | 0.396 |
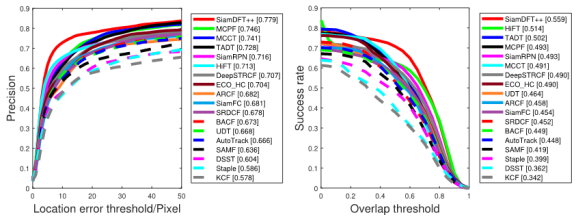
HiFT | 0.799 | 0.600 | 0.700 | 0.502 |
SiamDFT++ | 0.831 | 0.615 | 0.805 | 0.573 |
Trackers | DP | AUC | Trackers | DP | AUC |
|---|---|---|---|---|---|
SAMF | 0.470 | 0.326 | DeepSTRCF | 0.588 | 0.443 |
CCOT | 0.561 | 0.395 | MCCT | 0.605 | 0.407 |
KCF | 0.311 | 0.196 | SiamRPN | 0.626 | 0.462 |
SRDCF | 0.507 | 0.343 | DaSiamRPN | 0.665 | 0.465 |
Staple | 0.455 | 0.331 | ARCF | 0.544 | 0.381 |
SiamFC | 0.613 | 0.399 | UDT+ | 0.585 | 0.401 |
MCPF | 0.586 | 0.370 | AutoTrack | 0.512 | 0.349 |
BACF | 0.584 | 0.415 | TADT | 0.609 | 0.459 |
ECO_HC | 0.522 | 0.387 | HiFT | 0.763 | 0.566 |
DSiam | 0.603 | 0.391 | SiamDFT++ | 0.723 | 0.546 |
Trackers | DP | AUC | Trackers | DP | AUC |
|---|---|---|---|---|---|
SAMF | 0.519 | 0.340 | SiamRPN | 0.721 | 0.499 |
KCF | 0.468 | 0.280 | CCOT | 0.769 | 0.517 |
SRDCF | 0.512 | 0.363 | TADT | 0.693 | 0.464 |
MCPF | 0.664 | 0.433 | ARCF | 0.694 | 0.472 |
BACF | 0.590 | 0.402 | UDT | 0.602 | 0.422 |
ECO_gpu | 0.722 | 0.502 | UDT+ | 0.658 | 0.462 |
DeepSTRCF | 0.734 | 0.506 | AutoTrack | 0.717 | 0.479 |
MCCT | 0.725 | 0.484 | HiFT | 0.802 | 0.594 |
CFNet_conv2 | 0.616 | 0.415 | SiamDFT++ | 0.797 | 0.580 |
Method | UAV123 [2 6] | UAV20L [2 6] | DTB70 [2 7] | |||
|---|---|---|---|---|---|---|
DP | AUC | DP | AUC | DP | AUC | |
BT | 0.734 | 0.532 | 0.746 | 0.498 | 0.719 | 0.499 |
BT + F | 0.757 | 0.569 | 0.739 | 0.520 | 0.744 | 0.534 |
BT + F + AIFM | 0.773 | 0.579 | 0.653 | 0.519 | 0.757 | 0.543 |
BT + F + FDCM | 0.780 | 0.582 | 0.662 | 0.523 | 0.771 | 0.558 |
SiamDFT | 0.786 | 0.593 | 0.677 | 0.548 | 0.783 | 0.560 |
SiamDFT++ | 0.798 | 0.601 | 0.695 | 0.555 | 0.797 | 0.580 |
UAVs | Unmanned Aerial Vehicles |
| [1] | Yang. S, Xu. J, Chen. H, et al, High-performance UAVs visual tracking using deep convolutional feature, Neural Computing and Applications, 2022, pp. 13539-13558. |
| [2] | Henriques. J. F, Caseiro. R, Martins. P, et al, High-speed tracking with kernelized correlation filters, IEEE Trans. Pattern. Anal. vol. 37, no.3, pp. 583-596, Mar. 2015. |
| [3] | Bertinetto. L, Valmadre. J, Golodetz. S, et al, Staple: Complementary learners for real-time tracking, presented at the Proceedings of the IEEE conference on computer vision and pattern recognition, Jun.2021, pp. 1401-1409. |
| [4] | Bertinetto. L, Valmadre. J, Henriques. J. F, et al, Fully-convolutional siamese networks for object tracking, European conference on computer vision, Nov. 2016, pp. 850-865. |
| [5] | Danelljan. M, Hager. G, Khan. F, et al, Accurate scale estimation for robust visual tracking, presented at British Machine Vision Conference, Sep. 2014, pp. 1-5. |
| [6] | Kiani. Galoogahi. H, Fagg. A, Lucey. S, Learning background aware correlation filters for visual tracking, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Oct.2017, pp. 1135-1143. |
| [7] | Li. F, Tian. C, Zuo. W, et al, Learning spatial-temporal regularized correlation filters for visual tracking, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun.2018, pp. 4904-4913. |
| [8] | Li. B, Yan. J, Wu. W, et al, High performance visual tracking with siamese region proposal network, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2018, pp. 8971-8980. |
| [9] | Wang. N, Song. Y, Ma. C, et al, Unsupervised Deep Representation Learning for Real-Time Tracking, International Journal of Computer Vision, Jun. 2021, pp. 400-418. |
| [10] | Li. X, Ma. C, Wu. B, et al, Target-Aware Deep Tracking, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2019, pp. 1369-1378. |
| [11] | Li. B, Wu. W, Wang. Q, et al, Siamrpn++: Evolution of siamese visual tracking with very deep networks, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun.2019, pp. 4282-4291. |
| [12] | Hou. Q, Zhang. L, Cheng. M. M, et al, Strip pooling: Rethinking spatial pooling for scene parsing, presented at Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2020, pp. 4003–4012. |
| [13] | Wang. Q, Wu. B, Zhu. P, et al, ECA-Net: Efficient channel attention for deep convolutional neural networks, presented at 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2020. |
| [14] | Li. Y, Zhu. J, A scale adaptive kernel correlation filter tracker with feature integration, presented at European conference on computer vision, Mar. 2015, pp. 254-265. |
| [15] | Danelljan. M, Robinson. A, Khan. F. S, et al, Beyond correlation filters: Learning continuous convolution operators for visual tracking, presented at European conference on computer vision, Sep. 2016, pp.472-488. |
| [16] | Danelljan. M, Bhat. G, Shahbaz. KhanF, et al, Eco: Efficient convolution operators for tracking, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jul. 2017, pp. 6638-6646. |
| [17] | Cao. Z, Fu. C, Ye. J, et al, HiFT: Hierarchical Feature Transformer for Aerial Tracking, presented at Proceedings of the IEEE/CVF International Conference on Computer Vision, Oct. 2021, pp. 15457-15466. |
| [18] | Chen. S, Xie. E, Ge. C, et al, CycleMLP: A MLP-like Architecture for Dense Visual Predictions, IEEE Transactions on Pattern Analysis and Machine Intelligence, Nov. 2023, pp. 1-17. |
| [19] | Zheng. Z, Wang. P, Liu. W, et al, Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression, presented at Proceedings of the AAAI Conference on Artificial Intelligence, Feb. 2020, pp. 12993-13000. |
| [20] | Li. Y, Fu. C, Ding. F, et al, Auto Track: Towards high-performance visual tracking for UAV with automatic spatio-temporal regularization, presented at Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Jun. 2020, pp. 11923-11932. |
| [21] | Wang. N, Zhou. W, Tian. Q, et al, Multi-cue correlation filters for robust visual tracking, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jun. 2018, pp. 4844-4853. |
| [22] | Zhang. T, Xu. C, Yang. M. H, Multi-task correlation particle filter for robust object tracking, presented at Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Jul. 2017, pp. 4335-4343. |
| [23] | Danelljan. M, Hager. G, Shahbaz. Khan. F, et al, Learning spatially regularized correlation filters for visual tracking, presented at Proceedings of the IEEE International Conference on Computer Vision, Dec.2015, pp. 4310-4318. |
| [24] | Yang. K, He. Z, Pei. W, et al, Siam Corners: Siamese corner networks for visual tracking, IEEE Transactions on Multimedia, vol. 24, pp.1956-1967, Apr. 2021. |
| [25] | Xu. Y, Wang. Z, Li. Z, et al, Siamfc++: Towards robust and accurate visual tracking with target estimation guidelines, presented at Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no.07, pp. 12549-12556, Apr. 2020. |
| [26] | Mueller. M, Smith. N, Ghanem. B, A benchmark and simulator for uav tracking, presented at European conference on computer vision, Sep. 2016, pp. 445-461. |
| [27] | Li. S, Yeung. DY, Visual object tracking for unmanned aerial vehicles: a benchmark and new motion models, presented at Proceedings of the AAAI conference on artificial intelligence, Feb. 2017, pp. 4140-4146. |
| [28] | Huang. Z, Fu. C, Li. Y, et al, Learning aberrance repressed correlation filters for real-time UAV tracking, presented at Proceedings of the IEEE/CVF International Conference on Computer Vision, Oct. 2019, pp. 2891-2900. |
| [29] | Yang. S, Chen. H, Xu. F, et al, High-performance UAVs visual tracking based on siamese network, The Visual Computer, 2021. |
APA Style
Zhao, S., Chen, Y., Yang, S. (2024). UAV Visual Tracking with Enhanced Feature Information. Automation, Control and Intelligent Systems, 12(2), 35-47. https://doi.org/10.11648/j.acis.20241202.12
ACS Style
Zhao, S.; Chen, Y.; Yang, S. UAV Visual Tracking with Enhanced Feature Information. Autom. Control Intell. Syst. 2024, 12(2), 35-47. doi: 10.11648/j.acis.20241202.12
AMA Style
Zhao S, Chen Y, Yang S. UAV Visual Tracking with Enhanced Feature Information. Autom Control Intell Syst. 2024;12(2):35-47. doi: 10.11648/j.acis.20241202.12
@article{10.11648/j.acis.20241202.12,
author = {Shuduo Zhao and Yunsheng Chen and Shuaidong Yang},
title = {UAV Visual Tracking with Enhanced Feature Information
},
journal = {Automation, Control and Intelligent Systems},
volume = {12},
number = {2},
pages = {35-47},
doi = {10.11648/j.acis.20241202.12},
url = {https://doi.org/10.11648/j.acis.20241202.12},
eprint = {https://article.sciencepublishinggroup.com/pdf/10.11648.j.acis.20241202.12},
abstract = {Unmanned aerial vehicles (UAVs) visual tracking is an important research direction. The tracking object is lost due to the problems of target occlusion, illumination variation, flight vibration and so on. Therefore, based on a Siamese network, this study proposes a UAVs visual tracker named SiamDFT++ to enhance the correlation of depth features. First, the network width of the three-layer convolution after the full convolution neural network is doubled, and the appearance information of the target is fully utilized to complete the feature extraction of the template frame and the detection frame. Then, the attention information fusion module and feature deep convolution module are proposed in the template branch and the detection branch, respectively. The feature correlation calculation methods of the two depths can effectively suppress the background information, enhance the correlation between pixel pairs, and efficiently complete the tasks of classification and regression. Furthermore, this study makes full use of shallow features to enhance the extraction of object features. Finally, this study uses the methods of deep cross-correlation operation and complete intersection over union to complete the matching and location tasks. The experimental results show that the tracker has strong robustness in UAVs short-term tracking scenes and long-term tracking scenes.
},
year = {2024}
}
TY - JOUR T1 - UAV Visual Tracking with Enhanced Feature Information AU - Shuduo Zhao AU - Yunsheng Chen AU - Shuaidong Yang Y1 - 2024/08/15 PY - 2024 N1 - https://doi.org/10.11648/j.acis.20241202.12 DO - 10.11648/j.acis.20241202.12 T2 - Automation, Control and Intelligent Systems JF - Automation, Control and Intelligent Systems JO - Automation, Control and Intelligent Systems SP - 35 EP - 47 PB - Science Publishing Group SN - 2328-5591 UR - https://doi.org/10.11648/j.acis.20241202.12 AB - Unmanned aerial vehicles (UAVs) visual tracking is an important research direction. The tracking object is lost due to the problems of target occlusion, illumination variation, flight vibration and so on. Therefore, based on a Siamese network, this study proposes a UAVs visual tracker named SiamDFT++ to enhance the correlation of depth features. First, the network width of the three-layer convolution after the full convolution neural network is doubled, and the appearance information of the target is fully utilized to complete the feature extraction of the template frame and the detection frame. Then, the attention information fusion module and feature deep convolution module are proposed in the template branch and the detection branch, respectively. The feature correlation calculation methods of the two depths can effectively suppress the background information, enhance the correlation between pixel pairs, and efficiently complete the tasks of classification and regression. Furthermore, this study makes full use of shallow features to enhance the extraction of object features. Finally, this study uses the methods of deep cross-correlation operation and complete intersection over union to complete the matching and location tasks. The experimental results show that the tracker has strong robustness in UAVs short-term tracking scenes and long-term tracking scenes. VL - 12 IS - 2 ER -
School of Electric and Information, Southwest Petroleum University, Chengdu, China
School of Automation, Chongqing University, Chongqing, China
School of Electric and Information, Southwest Petroleum University, Chengdu, China
Information